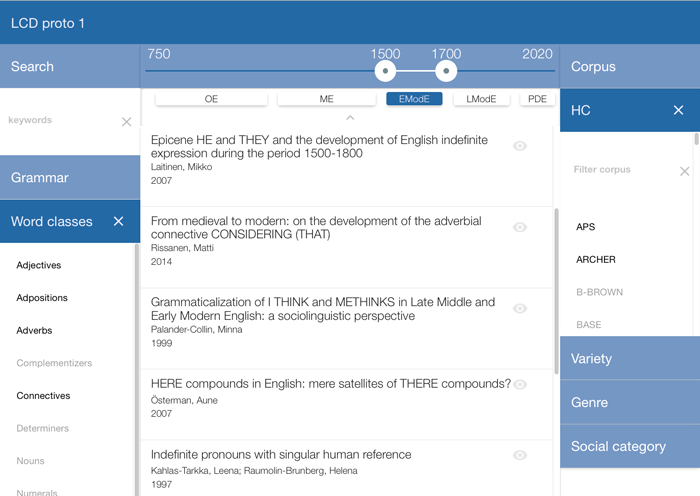
What is included in a Language Change Database entry?
The Language Change Database (LCD) is an upcoming open-access resource that draws together earlier corpus-based research on English historical linguistics. The LCD provides a fully searchable online environment, where all studies are annotated according to a number of categories (e.g. grammar, corpora, diachronic and regional coverage). Each LCD entry includes:
The LCD is currently in a beta stage, and it includes c. 300 entries that have been selected and prepared by the research team. Later the database will be opened to the wider research community, and researchers will be able to add their own studies into the database directly. Please check our News section for more up-to-date information on the status of the database. See also our publications and presentations.
Why do we need the Language Change Database?
Empirical work on language change is fragmented, and some of it is hard to come by. The aim of the LCD is to make linguistic research more accessible and cumulative by providing comparative, real-time baseline data from earlier corpus-based studies on the history of English. In addition to historical linguists in general, the data in the LCD may be useful to researchers interested in e.g. statistical modelling, systematic reviews, replication of earlier research with other data sets, and sociolinguistic typologies.
The Language Change Database is developed by the members of the project "Reassessing language change: the challenge of real time", which is funded by the Academy of Finland (2014-2018). For more information on the project members, see the People page.